


噬菌体展示技术是一种高效基因表达筛选技术,将外源蛋白或多肽与特定的噬菌体衣壳蛋白融合,展示在噬菌体表面并保持相对独立的空间构象和生物活性,有利于靶分子的特异性识别及结合,从而实现基因型和表达型的统一。噬菌体展示技术因其独特的优势,现已广泛应用于抗原表位分析、单克隆抗体的制备、抗体人源化、药物筛选、疫苗研制以及免疫学疾病诊断、治疗等科学研究领域。噬菌体技术为啥这么好用?为了一探究竟,我们先来弄清噬菌体是个啥?噬菌 ...
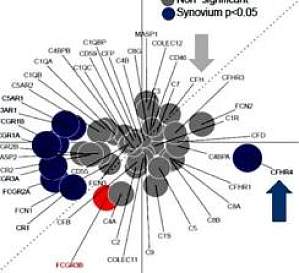
类风湿关节炎(RA)是一种以滑膜增生和炎症为特征的自身免疫性疾病。在血清阳性 RA 中发现自身抗体表明,由于关节中局部存在免疫复合物,补体系统激活可能发挥病理生理作用。尽管在开发类风湿关节炎新疗法方面取得了巨大进展,但目前尚无基于补体系统的疗法被批准用于临床治疗。来自美国科罗拉多大学安舒茨医学院、英国威廉哈维研究所实验医学和风湿病学中心、伦敦玛丽女王大学伦敦医学和牙科学院和卡迪夫大学医学院的研究人员,为了探索特定补体因子在早期类风湿关节炎中的作用机制及其临床应用可能性,对于PEAC(早期关节炎病理研究项目)的样本进行了研究。这项研究主要(1)检测了补体激活途径、受体和调节基因的表达,以及它们与滑膜和血液中 DAS28-ESR(关节疾病活动评分)临床疾病严重程度 的相关性的研究。(2)使用 Akoya Biosciences PhenoImager 8 色多重荧光免疫组化方案,检测了滑膜中关键蛋白的局部表达和病理生理变化,揭示了可能促进局部补体激活的激活和抑制因子的区域改变的重要证据。表 I. 分析补体和 FcgR 基因在PEAC研究项目样本血液和滑膜粘液中的表达水平研究发现作为临床疾病
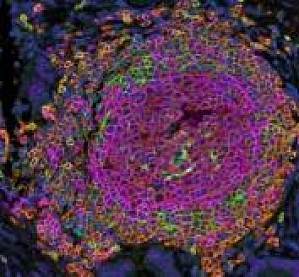
知名制药企业,CRO 公司,研究所等多家著名机构以多重免疫荧光整体方案为主要方法,对三个不同类型癌症患者的独立样本进行大规模回顾性分析,发现:(1) 较高密度的三级淋巴结构 (TLS) 的高密度性与 CD8+ T 淋巴细胞肿瘤浸润密度相关,是细胞杀伤性免疫反应激活的特征;(2) B 细胞和成熟 TLS 可预测接受免疫检查点抑制剂治疗的患者的预后;(3) 泛肿瘤/“肿瘤不可知”生物标志物:TLS 在 11 种不同肿瘤类型中的存在与 PDL-1 轴阻断功效相关;(4)为了更可靠地评估 TLS 成熟度,需要对 CD8、CD4、CD20、CD21 和 CD23 进行多参数分析。阻断 PD-1 受体与其主要配体 PD-L1 之间的相互作用具有显著抗癌作用,已有多种抗 PD-1 或抗 PD-L1 药物被批准用于多种实体瘤治疗。然而,大多数接受抗 PD-1 或抗 PD-L1 单克隆抗体的患者并没有从中获益。 免疫组织化学、肿瘤突变负荷 (TMB) 和微卫星不稳定性状态评估的 PD-L1 表达状态是迄今为止唯一被批准用于指导抗 PD-1 治疗的伴随诊断标志物。这些方法并不能有效区分出可能通过抗 PD-

越来越多的证据表明多重荧光免疫组化 (multiplex immunohistochemistry, mIHC),又称多重免疫荧光 (multiplex immunofluorescence, mIF) 技术的稳健性和预测价值。利用多重荧光免疫组化(mIHC)/ 多重免疫荧光(mIF)进行多重成像的空间生物标志物分析有望在发现研究和临床阶段的研究中得到广泛采用。 越来越多的实验室报道正在使用 Opal 多重荧光免疫组化优化为可重复的工作流程,为该技术的稳健性和预测价值提供了很多证据。我们在这里介绍收集到的一些经验和最佳实践,建立可重复的工作流程的四个关键步骤,包括抗体组合开发、染色、图像采集和分析,可节省研究人员的时间,并最终提高药物发现和开发的效率。 1. 建立最佳抗体组合使用 Opal 多重荧光免疫组化工作流程准确、可重复地鉴定组织中的不同细胞群及其关系,需要仔细设计、开发和优化用于多重生物标志物定量的抗体组合[1]。a 从预先设计的抗体组合开始要选择在多重荧光免疫组化中具有高灵敏度、特异性、再现性和优异性能的可识别所需靶标的抗体似乎并不那么容易。市面上可提供一些商品化的预先设计、
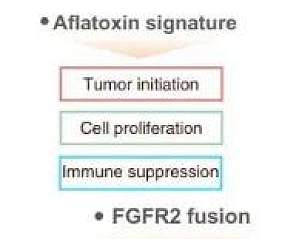
2022 年 1 月,权威期刊《Cell》子刊《Cancer Cell》(影响因子 31.743)杂志第一期刊登了来自国内团队复旦大学樊嘉院士、上海药物研究所周虎研究员、分子细胞科学卓越创新中心高大明研究员、复旦大学高强教授课题组等联合研究成果“Proteogenomic characterization identifies clinically relevant subgroups of intrahepatic cholangiocarcinoma”, 他们对来自 262 例肝内胆管癌患者肿瘤组织的基因组、转录组、蛋白质组等进行多组学联合分析,绘制了肝内胆管癌的多维分子图谱,为肝内胆管癌的精准治疗策略开发提供了新的技术思路。肝内胆管癌(ICC)是具有极大危害的原发性肝脏恶性肿瘤,并且手术切除率低且缺乏有效的靶向和免疫治疗方案,对人类健康造成极大危害。研究表明肝内胆管癌具有高度异质性肿瘤微环境和基因突变,导致其具有高度侵袭性和不良预后。基于临床大样本的蛋白组为核心的多组学研究策略以全景视角揭示肿瘤的分子特征和潜在治疗策略。文中基于 PhenoImager 多色荧光技术方案对于肿瘤样
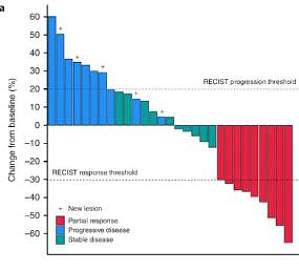
免疫检查点抑制剂( ICI )的发展带来了癌症治疗的一场革命。尽管从历史上看,肉瘤是第一种免疫疗法与临床获益相关的肿瘤类型,但这些 ICI 均未获批准用于治疗肉瘤患者。结合多项 PD-1/PD-L1 靶向治疗晚期肉瘤研究结果,在未经选择的人群中,临床获益非常有限。 来自法国波尔多大学、尼斯大学医院中心、贝尔戈尼研究所等多家研究机构和Explicyte的学者们联合报告了一项创新的生物标志物驱动的临床试验,该试验使用 TLS 作为生物标志物来选择癌症患者接受 ICI 治疗。富含 TLS 的队列的缓解率和 PFS 均显著高于 PEMBROSARC 研究的先前所有患者队列(分别为 30% 对 2% 和 4.9 对 1.5 个月)。这些结果与此前对 SARC028 研究中肿瘤样本的回顾性分析结果一致,表明晚期软组织肉瘤(STS) 中 TLS 的存在是一种潜在的预测生物标志物,可改善患者对派姆单抗治疗的选择。在PEMBROSARC 研究的临床试验设计中,研究者基于600 多个 STS样本的转录组数据定义了一个“高免疫”的肉瘤亚组,并使用多色免疫荧光验证样本中的肿瘤内 TLSs的组织特征,增加了一个
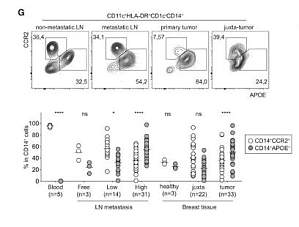
当前乳腺癌的发病率居所有女性恶性肿瘤首位,根据世界卫生组织国际癌症研究机构(简称 IARC )发布的《2021 年全球最新癌症负担》数据,全球乳腺癌新增人数达 265 万,已超越肺癌成为“全球第一大癌症”。目前乳腺癌的主要治疗方式有手术治疗、化学药物治疗、放射治疗、内分泌治疗及靶向治疗等,然而这些治疗手段并不能让所有患者都能有效获益,因而创新药物的研发与上市对于提高乳腺癌患者生存期,改变乳腺癌治疗格局具有深远意义。肿瘤相关巨噬细胞(tumor-associated macrophage,TAM)是肿瘤组织中浸润的巨噬细胞,主要由单核细胞分化而来。肿瘤细胞分泌的 CSF1、CCL2 等趋化因子能募集外周循环血中的单核细胞到肿瘤微环境(tumor microenvironment,TME)中,继而单核细胞分化成巨噬细胞。肿瘤组织中有大量炎症细胞浸润,包括TAM、淋巴细胞、肥大细胞等,其中 TAM 是最主要成分。巨噬细胞浸润是实体肿瘤的重要标志,然而TAM 在表型和功能上是异质的。前期研究表明 TAM 会造成肿瘤的预后不良。近日来自法国 PSL University,英国 The Unive
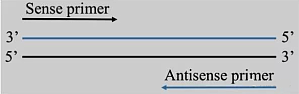
引|物|设|计20世纪后期发展的PCR技术改变了整个生物学研究的进程,其中引物设计的好坏直接关系到PCR的成败。1引物设计的基本原则引物设计的目的是为了找到一对合适的核苷酸片段,使其能有效地扩增模板DNA序列。在某些情况下(比如构建文库)是在不知道模板序列的情况下进行引物设计的,这个时候引物核苷酸序列与模板不是完全匹配。我们通常的引物设计都是在已知模板序列的情况下进行,如下图1所示:▲图1 引物设计示意图引物设计总 ...
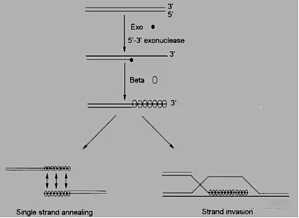
我们经常听到这样一句话“失去了才知道珍惜”。其实,只是因为失去了才知道它有多好。生物学家也利用这种方法来研究基因的功能,美其名曰↓基因敲除基因敲除(Gene Knockout)是上世纪80年代出现的一种新型遗传工程基因修饰技术,可针对某个特定基因进行改造,令其功能丧失,并研究其对相关生命现象造成的影响,从而推测该基因的生物学功能。经过近30年的发展,目前已经出现了很多前沿技术。当然,最经典的就数↓同源重组基因敲除技术细 ...
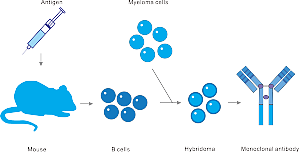
距1984年Milstein、Köhler因培养出第一代杂交瘤(hybridoma)被授予诺贝尔生理学奖至今已过去38个春秋,但由他们引领的抗体开发技术革命却从未停滞。借助分子生物学及基因工程技术的快速发展,各种高效抗体开发平台日趋完善。各公司都有不同的抗体开发平台,那么主流的抗体开发平台到底有几个?本文为大家全面介绍单克隆抗体制备比较成熟的三大技术服务平台:1.杂交瘤技术平台2.噬菌体展示抗体库技术平台3. ...

单细胞是流式细胞术对细胞进行分析检测的前提条件。在应用流式细胞术中,制备出合格的分散单细胞是流式细胞术样本制备技术中重要的一环。它既要求组织分散成为单个细胞,又要维持细胞的固有生物化学成分及生物学特性。

Annexin V 是一种钙离子依赖性磷脂结合蛋白,与磷脂酰丝氨酸 PS 有高度亲和力,可通过细胞外侧暴露的PS与凋亡早期细胞胞膜结合,将 Annexin V 标记上荧光染料利用流式细胞仪或荧光显微镜可检测细胞凋亡。

空白对照,即不添加任何荧光染料的对照管。设置空白对照,是为了区分细胞本底的自发荧光,及判断药物处理等外界因素是否会额外引入自发荧光。此外,空白管细胞为可能存在的最负阴性总群体的位置,能辅助电压的调节,避免上机时因电压过低导致的阴性细胞群压线。单阳对照即单阳管,是只添加一种荧光抗体的样本管。多色流式实验中,由于荧光素的发射波长覆盖范围较广,荧光可能产生重叠,对实验结果的数据分析造成一定的干扰。此种情况下,我们通常会设置单阳管进行补偿调节。同时,单阳管还可以辅助我们调节通道电压,防止信号超出接收范围。一般来说,实验panel有几种荧光,就需要设置几个单阳管。同型对照(Isotype Control),是指与使用的流式抗体具有相同种属来源、亚型、荧光标记物、使用剂量和浓度,但对目标靶点无特异性结合的抗体。同型对照通常用来消除抗体的非特异性结合造成的背景染色。FMO 对照是 Fluorescence Minus One(荧光扣除一)的缩写。在多色实验中,可能会出现某些通道信号难以区分的情况,主要原因是其他某个荧光对该通道的干扰很大,不能使用未染色的空白对照或全部用同型对照来设门。要记住,每增加

第一步、根据实验目的,选择目标 Marker。通过阅读相关文献,了解您实验需要选择哪些 Marker,以及这些 Marker 之间的逻辑关系(圈门的父子关系,比如 T 细胞CD3 是「父」,而 CD4 或者 CD8 就是子」)。这里列举了一些常见的细胞标志 Marker: 第二步、确认 Marker 的表达位置。对于细胞质或者细胞核的 Marker,需要对细胞进行固定破膜/破核膜。在做胞质或胞核 Marker 染色实验操作时,需要先染细胞表面 Marker,再对细胞进行固定破膜,最后对胞内或核内 Marker 染色。此时细胞表面的 Marker 尽量避免使用串联染料,因为「固定」容易对串联荧光素造成影响。一般来说,绝大部分 CD 分子指标,都是细胞表面指标;IL 白介系列、IFN-γ、TNF-α 等,属于胞内指标;而最常见的核内染色指标是 Foxp3。确认 Marker 表达位置的同时,我们还需要了解 Marker 的表达量。流式配色基本原则第一条是「强弱搭配」,我们需要通过表达量的强弱,来搭配荧光素的弱强。通常,根据待测细胞类型中,相应抗原的表达量,可以粗略地将抗原分子分为三类:1.

流式配色遵循以下基本规则:强弱搭配、选择干扰少的荧光组合、使分析的复杂程度降到最低、谨慎使用串联染料、注意环境因素对荧光素的影响。

一、样本准备详见流式细胞术样本制备技术、流式实验样本制备方法及注意事项收集细胞,200 目筛网过滤,收集滤液,300 g 离心 5 min,弃上清向细胞中加入适量细胞染色 buffer(或含 1%BSA 的 PBS),用移液枪轻轻吹打细胞重悬 二、细胞计数用血球计数板或其他仪器对悬液进行计数后,调整细胞浓度约为 1 × 107/mL 三、设置实验分组四、封闭 Fc 受体封闭 Fc 受体能减少染色过程中的非特异性染色。小鼠中,纯化的 CD16/CD32 单抗能和 FcγRⅢ/Ⅱ 结合,封闭非特异性染色,使阴性细胞的背景荧光降至未标记细胞的水平。加入 0.5-1 μg 纯的抗小鼠 CD16/32 单克隆抗体,室温孵育 10 分钟。对于人和大鼠,可直接使用过量的,与荧光抗体相同来源和亚型的纯化 Ig 或者与目标种属相同来源的血清进行阻断,或者用商业化的 Fc 受体阻断剂。 五、细胞染色按照说明书的推荐用量加入荧光标记抗体,混匀后置于 4℃,避光孵育 30 分钟。加入细胞染色 buffer (或含 1%BSA 的 PBS)重悬细胞,300g 离心细胞悬液 5 分钟,弃掉上清。加入 200μL
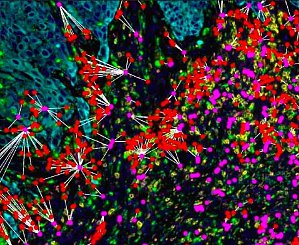
在《空间表型特征:表征实体肿瘤和预测免疫治疗反应的新型生物标志物》白皮书中介绍了基于 mIF 的空间表型特征作为新一代生物标志物发现的案例,意义和价值。


对很多初学者来说,发表SCI论文似乎遥不可及。为了提高SCI论文发表的中稿率,本文重点介绍SCI论文发表的五大要素,希望对大家有所帮助。 1、论文的创新性和逻辑性并不是每一篇文章都能发表在SCI期刊,首先论文选题时要具备一定的创新性,要有自己的论点和能阐明自己观点的数据,文章组织要有科学性,数据链条要有逻辑性,统计分析要有严谨性。有的人可能会有疑问:什么样的论文算是有创新性?这里举例:有时候一些临床类的医学论文,要凸显创新性并没有想象中的难,病例样本的不同就可以作为创新的一点,比如说Chinese population。另外就是数据统计问题,严密的数据统计分析是文章立据的基石,采用国际通用的分析方法,什么样的分析可以用t检验,什么样的样本需要用单因素方差分析以及分析是否有显著性差异等等,都要弄清楚。 2、论文写作对非英语母语国家的科研工作者来说,论文的英语写作是一个需要注意的问题。如果一篇文章语言语法太糟糕,可能编辑和审稿人还来不及审视其中的创新性就直接拒稿。论文写作不是一朝一夕就能搞定的问题,没有特别的捷径,需要多看文献和日常积累。那么我们能不能直接照搬国外文章的句子为己用呢?一般情

综述,顾名思义,就是在某一时间内,对某个领域内大量研究论文中的数据、资料和主要观点进行梳理、归纳、总结和展望,将该领域的进展和现状呈现于读者面前。综述虽然属于 “二手研究”,但能让读者在短时间内掌握某个领域的研究动态,因此有一定的学术价值。正因如此,多数学术杂志都会留出一定的版面,用于刊登综述。在过去几年,笔者曾和同事们在SCI杂志上发表过多篇综述,对于医学综述的写作有一定的心得体会。在此,笔者拟分享自己在SCI杂志上发表综述的心得体会,以期为有撰写综述计划的同行提供参考。 01、写作综述对科研新手来说是一种锤炼在已有很高造诣的专家眼中,综述的价值显然不及论著。因为论著反应了自己实实在在的科研成果,而综述只能证明自己阅读和整理了他人的研究成果。也正因如此,很多专家会在多种场合有意无意地流露出对综述的不屑。受此影响,很多科研新手也对综述写作不感兴趣。笔者认为这种思维和观念有待商榷,因为科研本身是分层次和等级的:对于掌握了大量资源,已经有很高造诣的研究者,目标当然是在高水平的杂志上发表论著;但是对于科研新手,完全可以将短期目标设定为撰写和发表一篇SCI综述。可以想象,对于刚刚涉足科研的新手
关于丁香通
公司信息
个人用户
企业机构


