


- 询价
- 杭州
- T细胞免疫组库(T cell Repertoire,TR)是指在任何指定时间,某个个体的免疫系统中所有功能多样性T细胞的总和。T细胞免疫组库测序(T cell Repertoire Sequencing, TR-SEQ)是以 T 淋巴细胞为研究目标,以PCR技术来扩增T细胞受体(TcR1)的全基因序列,再结合高通量测序技术,全面评估免疫系统的多样性,深入挖掘免疫组库与疾病的关系。 T 细胞属于人体免疫细胞,它在肿瘤免疫治疗,自身免疫疾病以及移植耐受等方面发挥着重要的作用。每个 T 细胞都有自己特殊的 T 细胞受体 (TcR),就像每一个细胞的身份证。对TcR测序分析可以准确监测我们免疫系统对疾病和治疗的反应,可以帮助科研者了解疾病与免疫系统的相互作用。
- 2026年07月15日

企业认证
相关产品推荐更多 >



万千商家帮你免费找货
0 人在求购买到急需产品
- 详细信息
- 询价记录
- 技术资料
- 服务名称:
T细胞(TCR)免疫组库全长测序 TR-Seq
- 提供商:
杭州艾沐蒽生物科技有限公司
背景介绍
T细胞免疫组库(T cell Repertoire,TR)是指在任何指定时间,某个个体的免疫系统中所有功能多样性T细胞的总和。T细胞免疫组库测序(T cell Repertoire Sequencing, TR-SEQ)是以 T 淋巴细胞为研究目标,以PCR技术来扩增T细胞受体(TCR)的全基因序列,再结合高通量测序技术,全面评估免疫系统的多样性,深入挖掘免疫组库与疾病的关系。
T 细胞属于人体免疫细胞,它在肿瘤免疫治疗,自身免疫疾病以及移植耐受等方面发挥着重要的作用。每个 T 细胞都有自己特殊的 T 细胞受体 (TCR),就像每一个细胞的身份证。对TcR测序分析可以准确监测我们免疫系统对疾病和治疗的反应,可以帮助科研者了解疾病与免疫系统的相互作用。TCR 作用是识别抗原。T 细胞通过细胞表面的 TcR 来识别抗原呈递细胞带来的抗原,每一个 T 细胞含有一个特异的 TcR 用来识别相对特异的抗原。T 细胞通过 TcR 基因的重组从而达到其多样化 (Diversity) 的特点(如下图),并可识别各种抗原与之反应。
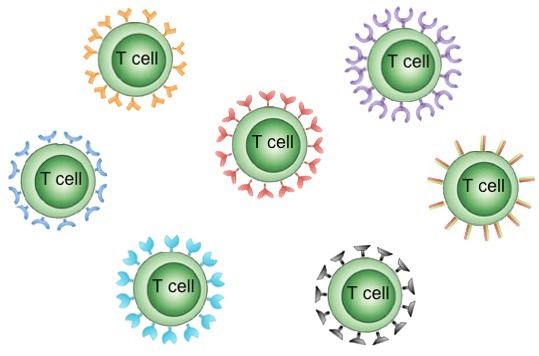
TCR是高度多样化的异二聚体表面受体,使T细胞能够提供针对各种不同病原体的保护,功能性TCR由两条配对的蛋白链组成,其中有α链和β链,或γ链和δ链。
TCR链包含一个能够识别抗原的N端可变区和一个C端恒定区。可变区由可变(V)、多样性(D)和连接(J)基因片段通过有序的V(D)J重组过程组装而成,其中每个基因片段的一个等位基因与其他基因片段的等位基因随机重组,形成功能性抗原识别区(如下图)TCRα和γ链由V和J基因片段组成,而TCRβ和δ链还包括D基因片段,结构更加多样化。基因片段的整体组合多样性伴随着连接多样性,这是由基因片段之间连接处核苷酸的随机添加或删除所决定的。组合和连接的多样性赋予T细胞大量的抗原特异性,可能占1015到1020个TCR链。
每个TCR链的可变结构域有三个互补决定区(CDR): CDR1、CDR2和CDR3。CDR1和CDR2,由V基因片段编码,主要通过与MHC的保守a-螺旋接触促进TCR和MHC之间的相互作用。CDR3 (Complementarity Determining Region 3)是由V和J或D和J基因片段的之间编码,导致了高变异性。该区域负责结合MHC呈递的抗原肽。由于其与抗原的直接相互作用和固有的高变异性,CDR3区为TCR的特异性提供了丰富的多样性,因此是TCR测序常用的靶点区域。
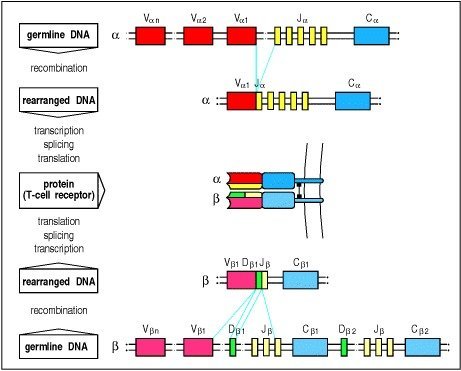
Immunobiology: The Immune System in Health and Disease. 5th edition. Janeway CA Jr, Travers P, Walport M, et al.
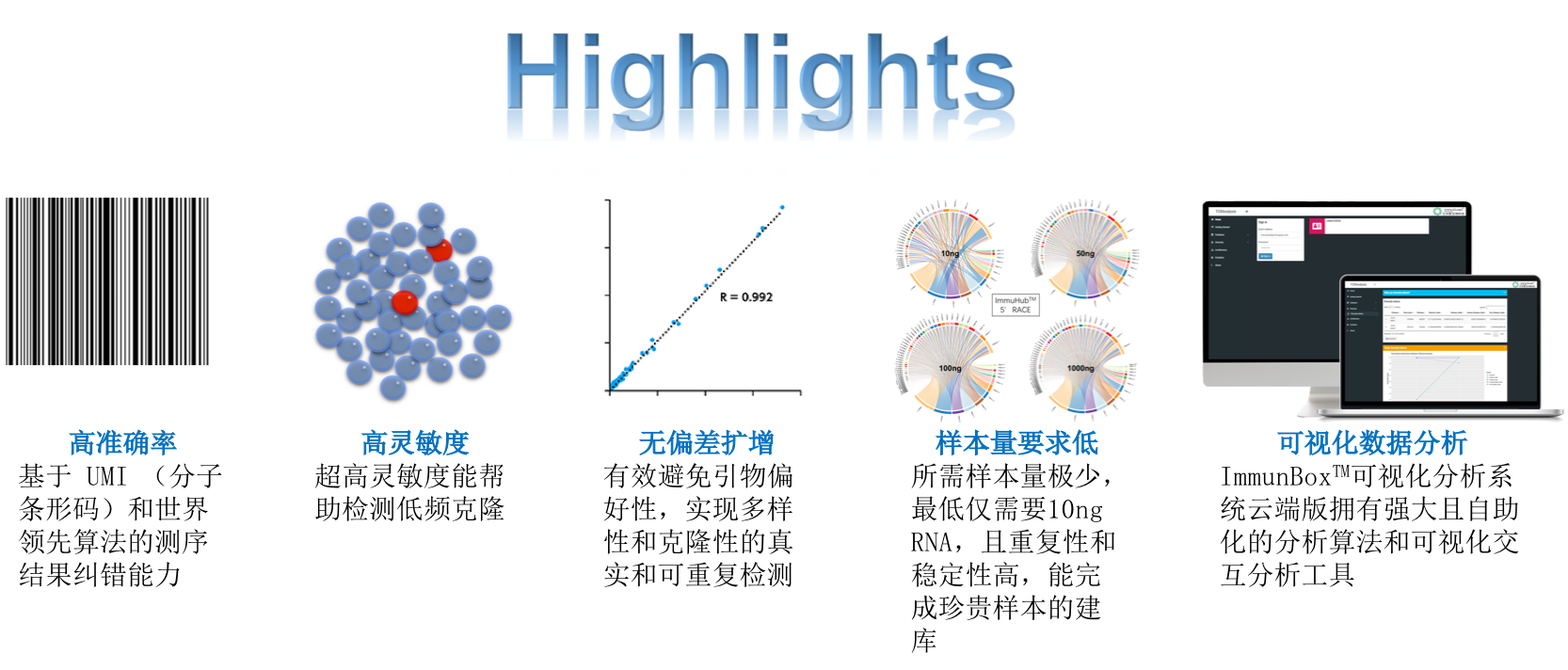
ImmuHub®通过基于第二代高通量基因测序技术为血液、骨髓或组织样本提供非常全面的 TcR 测序分析。我们会对测序后数据进行详细得生物信息学处理和数据分析,并且能保证每个样本的测序过程和分析结果在整个实验中的一致性,尽可能得减少实验结果误差。
ImmuHub®技术介绍
ImmuHub®是由艾沐蒽开发的一套灵活度极高的TCR和BCR二代测序平台。ImmuHub®技术平台是利用5'RACE或多重PCR技术,使我们能直接从基因组RNA或DNA来扩增TCR/BCR的全长序列或CDR3区序列,从而进行高通量测序和数据分析。ImmuHub®技术从实验设计到出具数据报告,为您的样本提供一个能获得全长测序或定量的免疫组测序解决方案,这个解决方案使您有能力解读适应性免疫系统的复杂性,帮助您发现适应性免疫系统的广度和深度,从而帮助您在肿瘤的生物标志物,治疗靶点,疗效监测及预后等应用研究中有更好的见解。
ImmuHub®技术平台目前为止发表了数十篇论文,其中包括:The New England Journal of Medicine(IF:158.5),Nature(IF:65), Signal Transduction and Targeted Therapy(IF:40), Cellular and Molecular Immunology(IF:24), Nature Communications (IF:17)等多篇高分杂志。


适用基因座
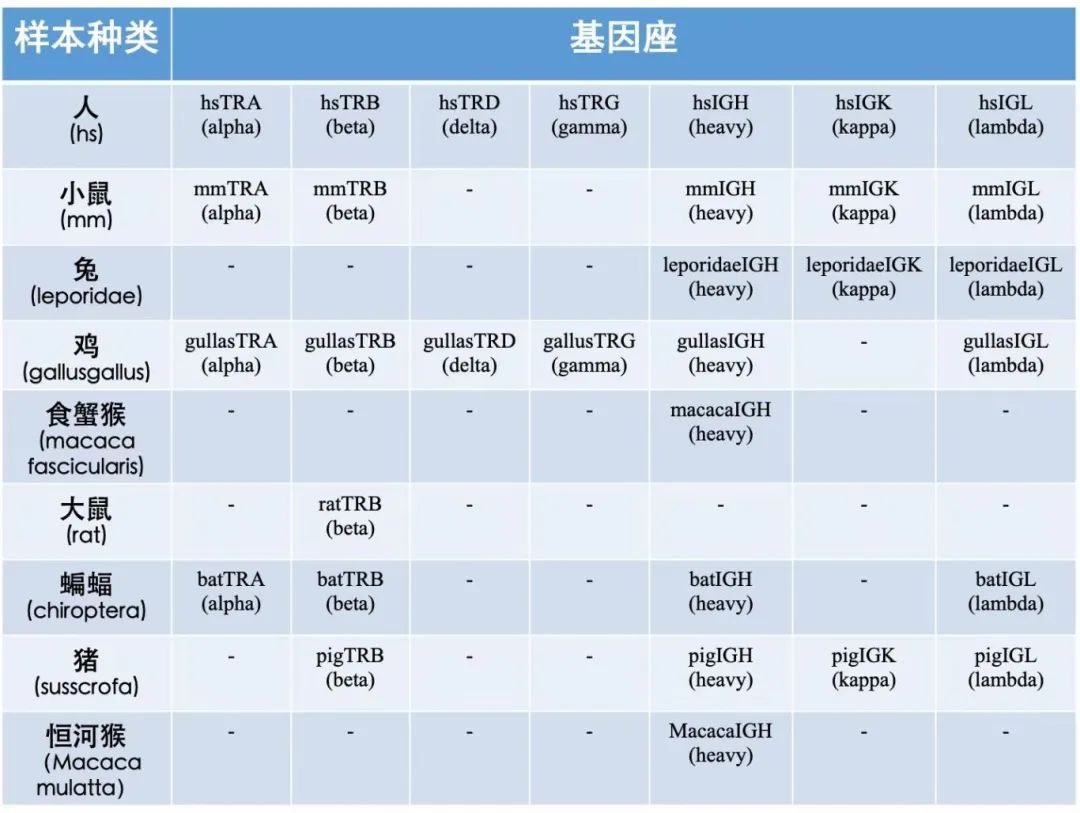
TCR测序技术路线

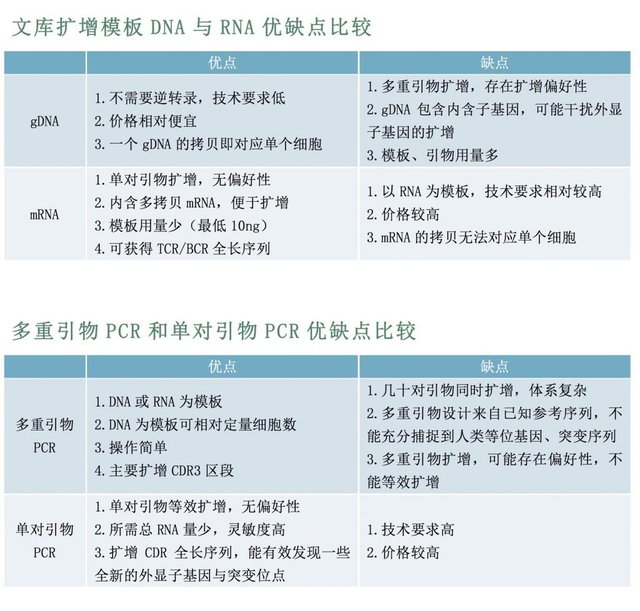
1.RNA+5'RACE+UMB
5'RACE,此方法仅适用于RNA作为模板,在cDNA合成过程中通过在5'端添加已知的adptor序列,随后使用此接头序列而不依赖于TCR cDNA中的简并引物,这大大降低了PCR偏差,不依赖于引物设计,具有更高的目标率。同时,艾沐蒽在逆转录cDNA过程中为每个RNA添加UMB标签,能确保免疫组库概况,反映原始样本中序列情况,而不受PCR扩增序列变多的影响,以及PCR或测序错误影响。5'RACE单对引物建库法能够得到包含完整TCR,这意味着可以保留完整的V基因序列,即可以扩增VDJ全长序列,同时又由于是根据C区设计引物,还可得到C基因信息。
2.DNA+多重
多重PCR适用于DNA和RNA模板,通常由两轮PCR组成(如果使用RNA作为模板,则在cDNA合成之后)。第一轮PCR扩增受体基因座,并添加已知序列作为第二轮的启动位点,其中包含测序接头和index。然而,第一次PCR的3'端,尤其是5'端的引物位点具有显著的高序列多样性,这就需要许多简并引物来扩增不同的TCR序列。因此,易引入PCR偏差,其中与引物更相似的受体序列被更有效地扩增, 艾沐蒽多重PCR的建库方法的主要优势就是针对公认的引物偏好性这一限制进行引物的调整和优化。首先设计了能覆盖所有基因的引物。通过引物调整和优化,降低多重PCR的引物偏好性。

ImmuHub®技术优势
1) 我们的检测分析更加全面准确,更少实验误差
-
很多实验室采取地是对 DNA 测序的方法,因为 gDNA 的提取与纯化相对简单,但如果通过 gDNA 来测序将会面临很多与准确性相关的问题。比如,TCR 上位于 C 区和 V-(D)-J 区之间有大量的内含子,这样会因为引物与不相关的内含子的非特异识别从而增加 PCR 扩增时候的背景杂质,导致引物的不必要消耗和增加结果误差。而我们能有效的提取 RNA 并且提供基于 RNA 的分析检测,这样除去了内含子,避免了以上提及的问题,还有提供的信息是基于表达的(有功能的)T 细胞受体 (TCR) 的优势。
-
大多数实验室的 PCR 扩增技术都是采用多重引物扩增的方法,多重引物的方法会影响样本备制时候的准确性。我们采用的是“单对”引物的方法,这样可以减少扩增时候的误差,同时能提供一个高精度的结果分析,也解决了多重引物法中混合引物扩增偏好性的问题。
-
多重引物扩增的方法是通过已知的 TCR 序列来设计的,在进行样本备制的时候常常会忽略一些未知的序列,往往这些未知的序列有可能会是科研新发现的关键。我们的“单对”引物是能扩增 TcR 中的全 V-(D)-J 序列(包括 FR1-4 和 CDR1-3),这样能有效的发现一些全新的外显子基因,使科研内容不仅仅局限于数据库里的已知基因。
2) 快速的检测分析
-
数以百万计的 TcR 序列都能够使用下一代高通量基因测序技术获得,并进行全面的数据分析。
-
深度的基因测序,并使用生物信息学分析算法对数据进行分析。
-
数据分析将会在收到样本的 8-12周内完成。
T 细胞受体(TCR)测序服务步骤
服务流程:客户提样本,通常为全血、骨髓、单个核细胞、分离后的T细胞、RNA/cDNA或者石蜡包埋的组织[FFPE],送达公司实验室后,实验室根据样本的情况,进行血液或骨髓的T细胞分离→ RNA 提取→ cDNA 合成→第二代基因测序→生物信息学处理→数据分析和出图→临床信息分析(如下图)。 45个工作日后客户获得测序结果报告。

TCR测序流程
• 提取样本 RNA
我们将从客户送来的样本里提取客户所需要的T细胞亚型的 RNA,RNA 质量监控在样本备置中有着非常重要的作用,我们的每一步都会通过先进的设备,如 TapeStation (Agilent Technologies, Inc.),对 RNA 和 cDNA 进行质量监控。如果样本质量不好,我们不会进行下一步,我们会联系客户或者使用其他方法获得更好质量的样本。
• cDNA 合成和基因扩增
我们合成 cDNA 将使用 5’ RACE PCR 技术来扩增 TCR 基因。

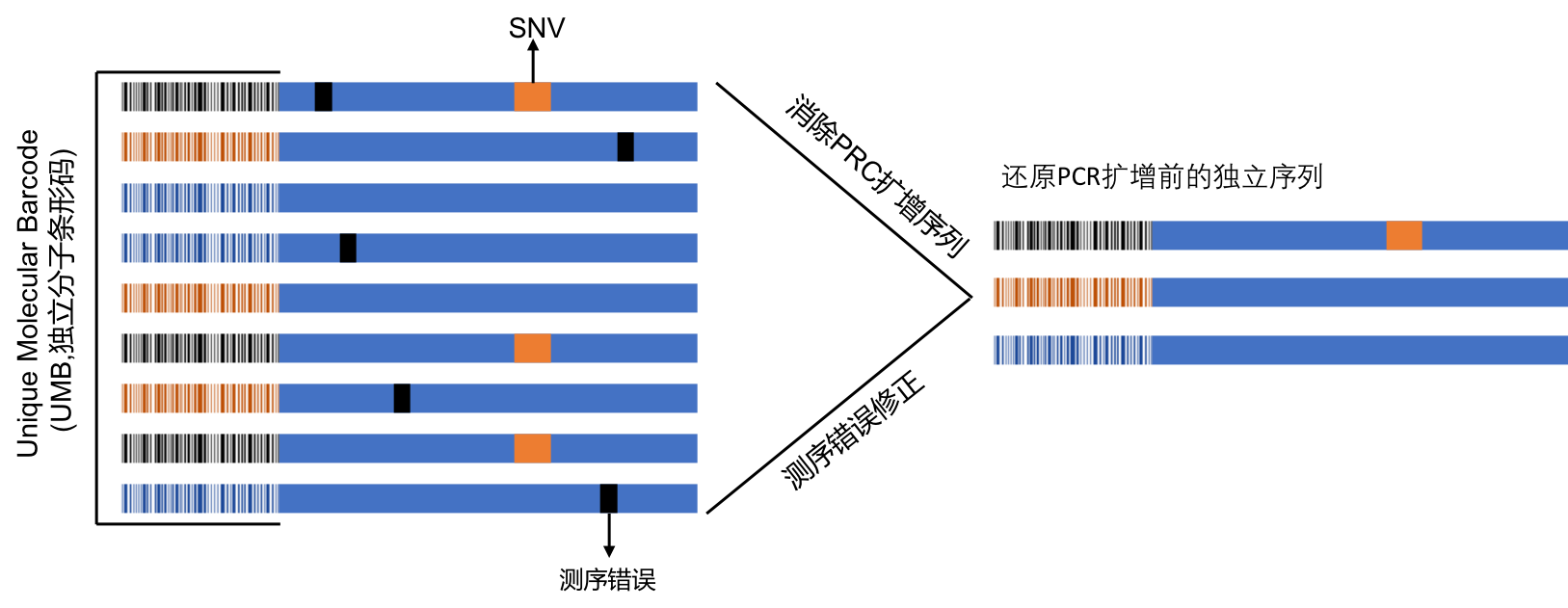
• 基于UMB的超强纠错
在原始RNA模板扩增前加入UMB(Unique Molecular Barcode,独立分子条形码)进行文库构建,可对后续PCR反应或测序过程中的错误进行有效纠正,还原真实的数据,完全杜绝PCR错误和测序错误,从而提高准确率。 模拟无PCR化测序,还原PCR之前的真实分子数量。
• 高通量测序
我们将使用 MiSeq® (Illumina Inc.) 2 × 300 bp pair-end 方法来对 TCR 进行测序,保证 TCR 的全长序列都可获得,亦可使用NovaSeq PE150/PE250以获得更大的通量和更便宜的价格。
• 数据分析
TCR 的测序数据将通过我们的生物信息学分析算法进行处理。
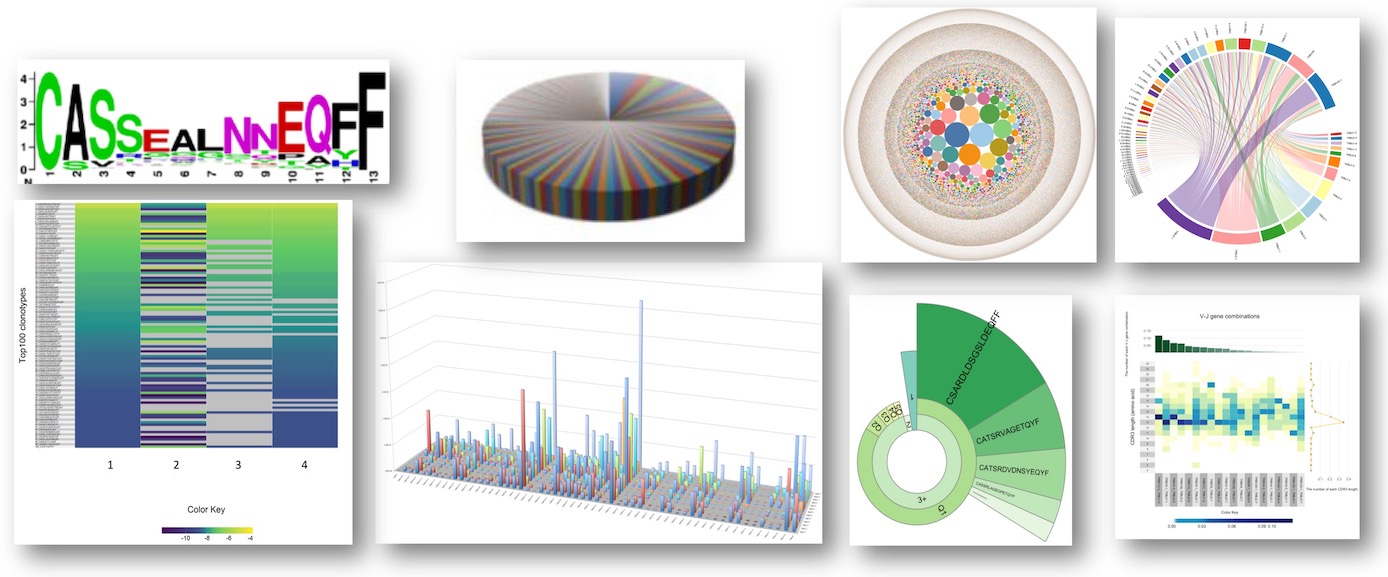
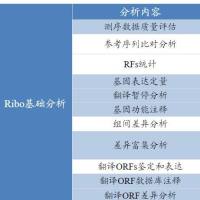
基本数据分析将会包含以下信息:
1.CDR3克隆鉴定、计数、频率(TCR种类数和FR1-4,CDR1-3 的序列
V-(D)-J-C gene ID 信息)
2.克隆性指数和多样性指数
3.CDR3核酸序列长度
4.气泡图
5.V/D/J基因频率分布柱状图
6.V/D/J/基因频率分布饼状图
7.V-J基因片段组合circos图
8.V-J基因片段组合使用森林图
9.V-J基因片段组合使用热力图
10.克隆频率分类呈现蜗牛图
11.全长克隆序列分析
12.TCR-抗原匹配注释
深度数据分析:
TcR状态的统计、总结、谱系等
-
计算样本的统计总结:序列读数、平均克隆种类大小,无功能克隆种类数等
-
计算样本每个V和J基因的使用率,绘制基于标准分数(z-Score)的热力图(heatmap)
-
计算CDR3克隆种类长度的高斯分布,绘制前N个最高表达CDR3克隆的谱系图
-
绘制V-J基因配对频率图、3D森林图
-
基于CDR3基因长度,计算和绘制V基因的分布图
样本TcR多态性和克隆性评价
-
计算、比较样本间多样性和克隆性 (计算 Shannon、Simpson、Berger-Parker指数)
-
绘制样本多态性、克隆性图谱
样本间TcR克隆种类重合、共享分析 (overlap and sharing)
-
计算两个样本TcR克隆种类的共享情况,追踪同一个病人治疗前后克隆种类变化
-
绘制两个样本间克隆种类配对比较图
我们也将按照客户的要求提供更多的分析和不同的数据报告形式,数据结果将以电子文档的形式传送给客户。
TCR测序的部分科研应用方向

【1.】 T细胞受体基因的专业术语起初是两个字母——“TR”,由国际人类基因命名委员会(HGNC)1999年审核通过。因而当提及到基因、基因座和链时,TR应该是最准确的描述。不过TcR是目前用得最广泛的。但是,大写的 ”TCR“ 缩写混淆了基因命名,应该避免。
想知道更多内容请访问艾沐蒽官网或邮件、电话联系
风险提示:丁香通仅作为第三方平台,为商家信息发布提供平台空间。用户咨询产品时请注意保护个人信息及财产安全,合理判断,谨慎选购商品,商家和用户对交易行为负责。对于医疗器械类产品,请先查证核实企业经营资质和医疗器械产品注册证情况。
- 作者
- 内容
- 询问日期
 技术资料
技术资料暂无技术资料 索取技术资料

