大家都在搜

| 编者按: 常规做RDA、CCA分析一般使用CANOCO软件或者R语言的Vegan包去做分析,前者太贵,后者复杂,肿么办? 欧易/鹿明云平台小工具: 别担心,云平台小工具来帮您轻松完成分析。 RDA或者CCA是基于对应分析发展而来的一种排序方法,属于限制性排序,对比主成分分析可以发现,其实冗余分析就是约束化的主成分分析,将对应分析与多元回归分析相结合,每一步计算均与环境因子进行回归,又称多元直接梯度分析。 RDA基于线性模型,CCA则是基于单峰模型。此分析是主要用来反映菌群与环境因子之间关系,可以检测环境因子、样本、菌群三者之间的关系或者两两之间的关系。 RDA或CCA模型的选择原则:先用Species Table数据做DCA分析,看分析结果中Axis Lengths of gradient的轴的大小,如果大于4.0,就应该选CCA,如果3.0-4.0之间,选RDA和CCA均可,如果小于3.0,RDA的结果要好于CCA。 云平台RDA/CCA小工具网址:https://cloud.oebiotech.cn/task/cca_rda_env/
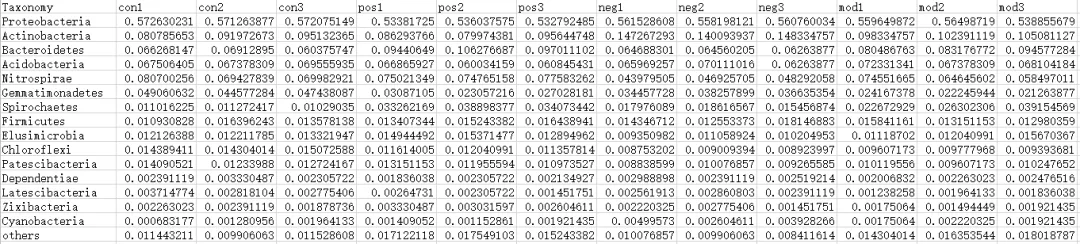
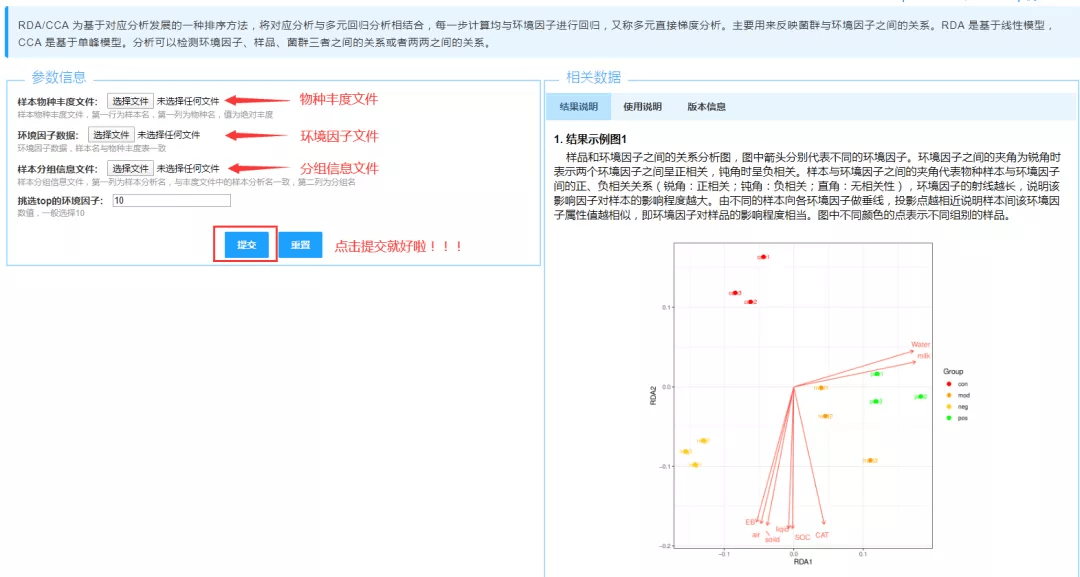
一.数据准备 需要的数据有物种的丰度数据、环境因子数据和分组信息数据,数据格式介绍如下: 1.物种相对丰度文件 物种相对丰度文件(tab分割文件)为必填参数。第一行为样本分析名,第一列为物种名,数值为物种在样本中的相对丰度。输入文件格式支持txt,xls和xlsx。
环境因子数据文件(tab分割文件)为选填参数。第一行为样本分析名,第一列为环境因子信息名。输入文件格式支持txt,xls和xlsx。
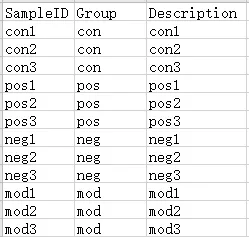
样本分组信息文件(tab分割文件)为选填参数。第一列为样本分析名,第二列为样本的分组名称(请注意表头Group大小写问题)。输入文件格式支持txt,xls和xlsx。
注: 1.输入的环境因子个数必须大于等于2,并且小于样本个数。 2.物种样本名称、环境因子样本名字和分组信息中样本名一定要保证一致。
就是这么简单,再也不用担心做不出RDA/CCA图啦!!
猜你想看 ◆生信分析—文献管理神器:如何快速从主流数据库中获取人/小鼠数据? ◆生信分析—数据库获取:如何快速从主流数据库中获取人/小鼠数据? ◆生信分析—可视化处理工具:你可以更美一些:SnapGene Viewer软件序列可视化操作 ◆生信分析:这个R包不太冷系列——GOplot(功能富集绘图) ◆生信分析:10行代码让你的相关性图貌美如花 ◆生信分析:对话百年名画--文章绘图配色高级又简单! ◆生信分析:只需3分钟Get“代谢通路分析神器” ◆生信分析:玩转生信—火山图中“亿点细节”,你会打造吗? ◆生信分析:【指南】Cytoscape之stringAPP蛋白互作分析详解 ◆生信分析:【教程】组学研究,用python快速实现PCA分析和绘图 ◆生信分析:组学研究,R语言实用技巧—热图,运用pheatmap包简单易懂快速汇图方法来袭~ ◆生信分析:【情人节】R语言—小提琴图的浪漫邂逅 END |

更有优质直播、研选好物、福利活动等你来!