- 移动端

Olink Proteomics品牌商
1 年
手机商铺
- NaN
- 0
- 1
- 2
- 1

推荐产品





公司新闻/正文
出色设计 + 优质数据:蛋白质组学研究设计指南(含 PEA 技术深度解析)
57 人阅读发布时间:2025-11-25 15:47
针对广大科研工作者的核心需求,本期推文聚焦蛋白质组学研究的两大关键维度 —— 邻位延伸分析(PEA)核心技术与科学研究设计,为大家带来从技术原理到实践落地的全流程干货。在 PEA 技术板块,我们将拆解其 “双重识别 + 核酸读取” 的独特机制,详解其在特异性、灵敏度等方面的突破性优势及完善质控体系,揭秘其如何攻克蛋白质组学领域的历史性难题;在研究设计板块,我们将理清研究问题与方案设计的逻辑关联,梳理研究流程关键节点,重点解析研究功效的优化策略,助力科研人员打造高质量蛋白质组学研究。
邻位延伸分析 (PEA) 技术
学习目标
-
深度理解 Olink PEA 技术的核心原理
-
掌握 PEA 技术在蛋白质检测中的核心优势
-
明晰 PEA 技术内置质量控制体系的关键作用
什么是 PEA 及其工作原理
邻位延伸分析(PEA)技术创新性地融合了抗体检测的特异性与 DNA 技术的高灵敏度,为蛋白质生物标志物发现提供了理想工具,将亲和力依赖的蛋白质测量技术提升至全新高度。该技术由 Olink Proteomics AB 公司商业化,广泛应用于 Olink 生物标记物 Panel 开发,通过将双重识别免疫测定与实时定量 PCR(qPCR)或二代测序(NGS)读数技术结合,实现了可扩展、超多重且高特异性的蛋白质定量检测,单次实验即可准确定量数千种蛋白质生物标记物(图 1至 图 4 为 PEA 技术机制与核心优势示意图)。
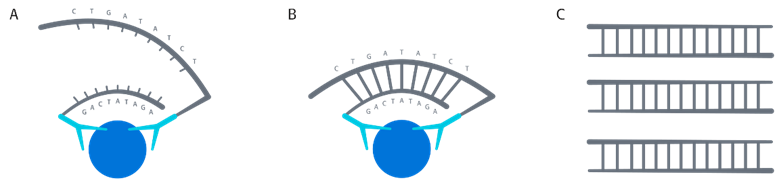
图 1. PEA技术读取前的主要步骤
具体工作流程(图 1):
-
标记有 DNA 寡核苷酸的特异性抗体对,在溶液中与目标抗原特异性结合;
-
结合后处于邻位的两条 DNA 寡核苷酸链发生杂交,随后在DNA 聚合酶作用下进行延伸反应;
-
新生成的含特异性条码的 DNA 片段,通过 PCR 扩增后,可采用 NGS 或 qPCR 技术进行读取与定量分析。
技术突破点(图2):传统免疫分析法进行多重检测时,易因抗体交叉反应导致结果偏差,而PEA 技术通过双重抗体识别与 DNA 条码标记的双重特异性验证,有效规避了交叉反应干扰,显著提升检测准确性。
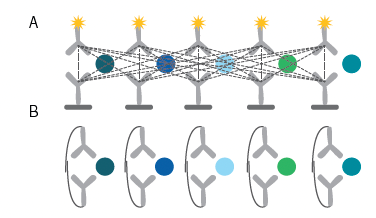
图2. 克服多重免疫检测的局限性
超高通量优势(图3):PEA 技术的扩增子分子设计包含一个正向和一个反向DNA 条码,该部分条码包含检测 ID 信息。第三部分 DNA 条码包含样本 ID 信息。仅需 2μL 血浆或血清样本,即可同时完成超过5000 余种蛋白质的检测,大幅降低样本消耗的同时提升检测效率。

图3. 通过 NGS读取每个蛋白和样品的条码
PEA 技术的内置质量控制体系(图 4):
为确保检测数据的可靠性与稳定性,PEA 技术建立了覆盖全流程的内置质量控制体系,对实验各环节进行严格监控:
-
样本对照品:用于评估实验的重复精度,确保同一样本检测结果的一致性;
-
阴性对照:精准测量每种蛋白质及整个样品板的背景信号水平,排除非特异性结合干扰;
-
IPC / 板间对照:用于不同检测板间数据的归一化处理,消除板间差异,保障多板实验数据的可比性;
-
全流程质控节点:涵盖免疫结合、DNA 延伸、PCR 扩增 / 检测等关键步骤的专项质控,全面监控实验流程的稳定性。

图4. PEA的质量控制体系
PEA如何解决蛋白质组学的历史性挑战
蛋白质组学研究长期面临灵敏度不足、特异性欠佳、样本消耗量大、动态范围有限四大核心难题,PEA 技术通过独特设计实现了全方位突破(图 5、图 6):
-
双重抗体识别增强特异性:需一对特异性抗体同时结合目标抗原才能启动后续反应,大幅降低非特异性结合概率,解决了传统方法特异性不足的问题;
-
PCR 扩增提升灵敏度:通过对目标信号的 PCR 扩增放大,实现低至 fg/mL 级别的蛋白质定量检测,突破传统免疫检测的灵敏度瓶颈;
-
优化设计降低样本消耗:采用高效的反应体系设计,样本需求量≤6μL,完美适配微量样本研究场景;
-
超宽动态范围覆盖:可检测的蛋白质浓度范围跨越 10 个数量级(fg-mg 级别),覆盖从低丰度细胞因子到高丰度结构蛋白的全范围检测需求,解决了蛋白质组学研究中动态范围有限的难题。
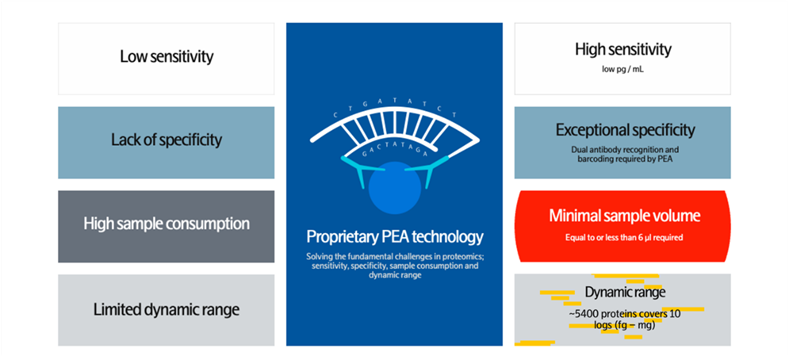
图5. Olink PEA如何解决蛋白质组学的历史性挑战
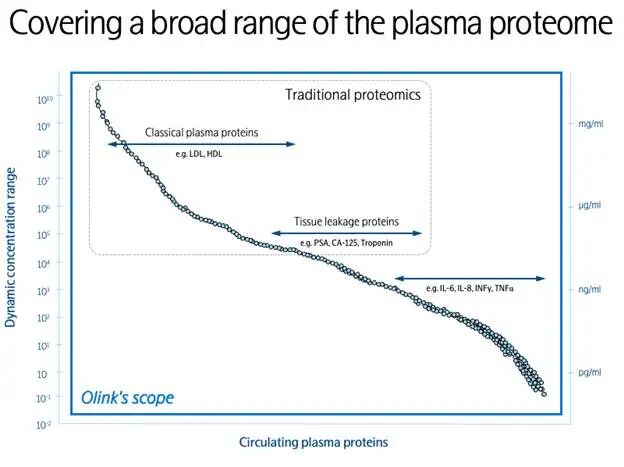
图6. PEA的动态范围
精准设计:提升蛋白质组学研究功效,获取可转化数据
学习目标
-
明确研究问题对研究方案设计的导向作用
-
掌握提升蛋白质组学研究功效的核心策略
蛋白质组学研究问题
研究问题决定了研究计划的核心框架与技术路径,蛋白质组学的应用场景广泛(图 7),不同研究目标对应差异化的设计方案:
-
遗传学研究:通过 pQTL(蛋白质数量性状位点)分析,借助蛋白质组学数据解析基因与蛋白质表达的关联机制;
-
临床预测:预测疾病进展轨迹及患者对治疗方案的响应程度,为精准医疗提供依据;
-
疾病早筛:发现疾病早期特异性生物标志物,实现疾病的早期诊断与干预;
-
标志物发现:挖掘新的疾病相关生物标志物及风险因子,为疾病机制研究与药物开发提供靶点。
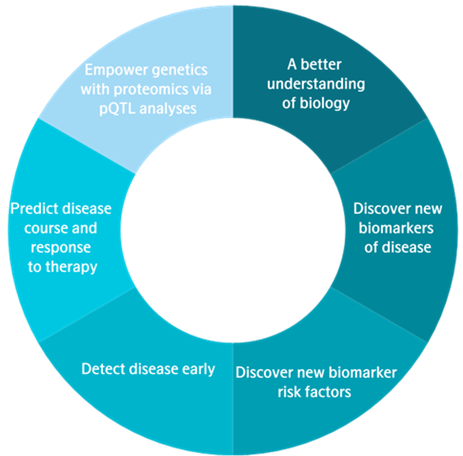
图7. 蛋白质组学的应用实例
蛋白质组学研究流程概述和方案设计
标准化研究流程(图 8):
从研究问题出发,遵循 “研究计划→研究设计→研究执行→统计分析→可操作数据” 的完整流程:
-
研究计划阶段:明确研究目标、筛选检测靶点、进行功效分析;
-
研究设计阶段:确定实验设计类型、样本分组策略、随机化方案;
-
研究执行阶段:完成样本选择、规范收集与处理、样本检测分析;
-
统计分析阶段:结合质量控制数据,进行专业的统计建模与差异分析,最终输出可转化的研究结论。
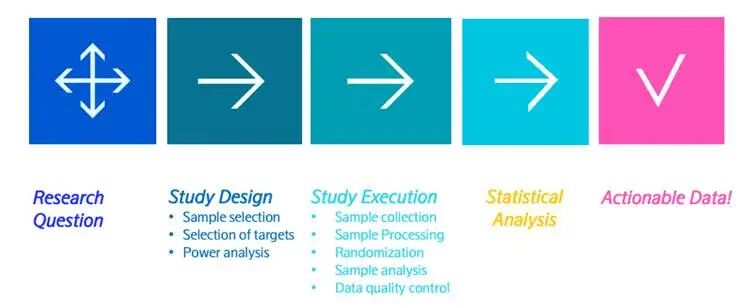
图8. 从研究的问题到可操作的数据:蛋白质组学研究流程概述
研究方案设计(图 9):
根据研究规模、时间维度及研究目的,可选择适配的设计方案:
-
小规模研究:单块检测板完成,通常包含 44 例病例与 44 例对照,设计简洁且效能明确,适用于初步探索性研究;
-
大型研究:多块检测板并行检测,样本量充足,统计功效高,适用于验证性研究或大规模人群研究;
-
连续研究:分批次处理样本,每批次数据可用于指导后续批次的分析方向,适用于逐步深入的探索性研究;
-
纵向研究:追踪同一患者多个时间点的样本,核心目标是分析蛋白质表达随时间的变化规律,适用于疾病进展监测或治疗效果评估研究

图 9. 不同蛋白质组学研究设计方案
研究设计的核心目标:
-
最大化统计功效:通过合理增加样本量,提升检测组间差异的概率;
-
最小化实验变量:通过标准化操作、随机化分组、设置对照等方式,减少生物学差异与技术差异对结果的干扰。
研究功效的关键认知与优化策略
研究功效的定义:
研究功效是指在给定效应值的前提下,正确检测出研究组间差异的概率。其核心影响因素包括:
-
效应值大小:即研究组间差异的标准化度量,取决于实际差异幅度及数据的标准差,是影响功效的核心因素;
-
样本量:样本量与研究功效呈正相关,合理增加样本量可提升功效;
-
数据分布特征:组间数据重叠程度越高,效应值越小,所需样本量越大才能达到相同功效。
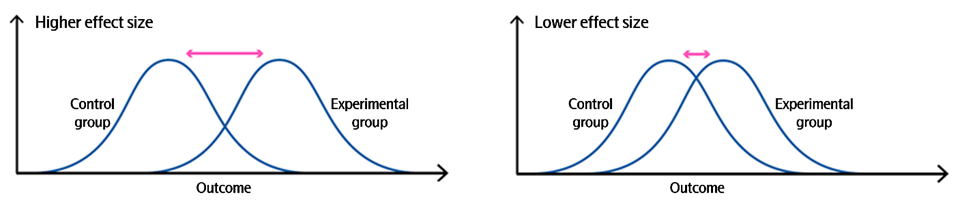
图 10. 研究的效应值大小和功效
效应值与样本量的关系(图 10、图 11):
-
高效应值场景:当实验组与对照组数据几乎无重叠,组间差异显著时,即使样本量较小,也能获得较高的研究功效;
-
低效应值场景:当组间数据重叠部分大于差异部分,效应值较小时,需大幅增加样本量才能保证足够的研究功效,以确保准确检测到真实差异;
-
常规设计标准:多数研究设计为 80% 的统计功效,即有 80% 的概率检测到组间的真实差异。
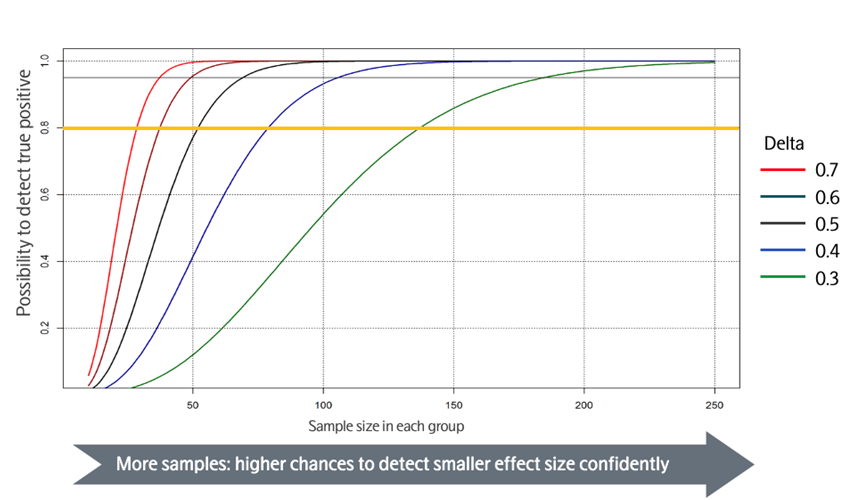
图 11. 对照组和实验组之间的功效计算示例
提升研究功效的实用技巧:
-
样本量优化:若各组样本量不均衡,优先增加最小组的样本量,可更高效地提升整体研究功效;
-
实验设计优化:采用配对设计(如自身前后对照),可有效减少个体生物学差异性,显著提升功效;
-
聚焦核心因素:效应值对功效影响最大,设计阶段可通过精准定义研究指标、减少数据变异,间接提升效应值;
-
大规模研究质控:开展多批次、跨时间点的大规模研究时,采用随机化分组或设置桥接样本,是保障数据可合并分析的关键;
-
专业支持获取:可向 Olink 数据科学团队咨询,获取个性化的研究功效分析建议;
-
工具辅助设计:利用 Olink 免费提供的功效计算工具(Olink Insight — Study Size Calculator),精准估算所需样本量,优化研究设计。
结语
本期推文系统梳理了 PEA 技术的核心原理、优势及质控体系,同时详解了蛋白质组学研究设计的关键逻辑与功效优化策略,为大家构建了从技术核心到实践应用的完整知识框架。这是我们蛋白质组学技术干货系列的开篇内容,后续将持续推出更具针对性的深度分享 —— 包括蛋白质组学实验设计的精细化规划、数据深度挖掘的实用方法、Olink 相关工具的 step-by-step 操作指南等。关注我们,获取前沿技术干货,助力您的蛋白质组学研究高效推进!